
近期,产业界的研究发现,模型推理在增强模型处理数学、编程等复杂问题的能力上取得了显著成效。但与此同时,现有的强化学习系统正遭遇众多难题。在这种情势下,新型异步强化学习系统是否能在该领域引发革命性的突破,还有待进一步的观察。
传统强化学习困境
多数强化学习算法在生成和训练过程中都严格遵循时间序列的顺序。这意味着每一轮的训练必须等待当前轮次的所有样本生成完成后才能开始。这种模式被称为同步强化学习。特别是PPO和GRPO等主流算法,对“最新策略数据”的依赖性较高,这无疑加大了系统设计的复杂性。算法要求,所采用的训练数据必须来自当前模型的最新版本,这一规定的目的是确保训练数据的策略保持一致。
新系统应运而生
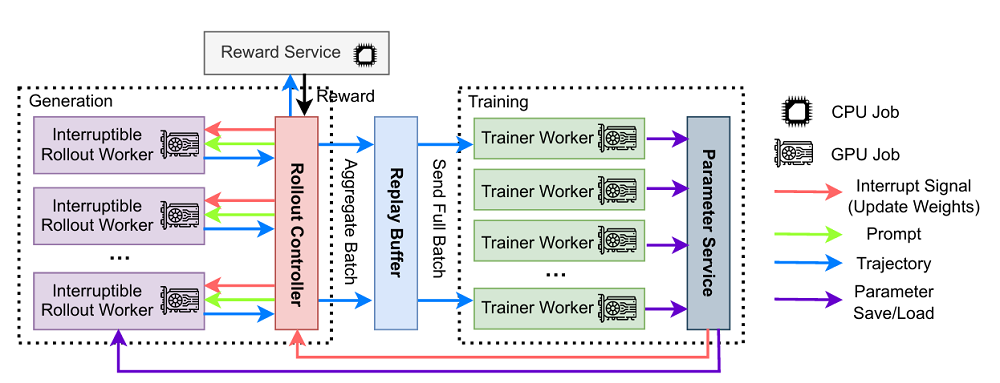
为应对所面临的挑战,AReaL - boba²这一针对高效大规模语言模型强化学习训练特别设计的异步强化学习系统应运而生。该系统由四个关键组成部分构成,其中“训练器(Trainer Workers)”这一模块负责不断从历史数据中抽取样本,并运用强化学习算法对模型进行更新,同时保存这些更新后的参数。
应对分布差异
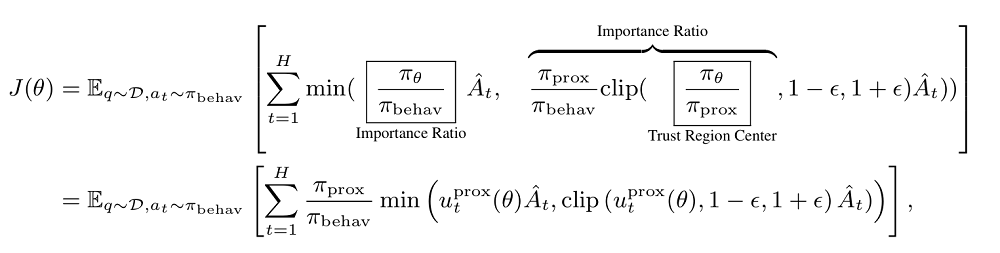
数据分布上,异步强化学习系统呈现出一定差异,这些差异可能源于使用旧版模型的不同训练批次,进而引发与现有模型的不匹配现象。为解决此问题,研究团队引入了最大允许滞后值“η”,其目的是调节生成数据时采用的策略版本与当前训练策略版本之间的差异。运用解耦的 PPO 算法对生成数据的行为策略进行加工,同时,对模型当前的近端策略进行独立处理。除此之外,还通过重要性采样技术对行为策略与近端策略之间的差异进行调节和减少。
高效近端策略
在理论研究中,通过复杂的技术途径,可以构建出与PPO解耦的近似策略。但鉴于大型语言模型在计算资源上的高消耗,AReaL - boba²在每次模型更新前,直接使用参数来作为近端策略。此方法不仅提高了异步训练的效率,同时确保了算法的收敛性和训练过程的稳定性。
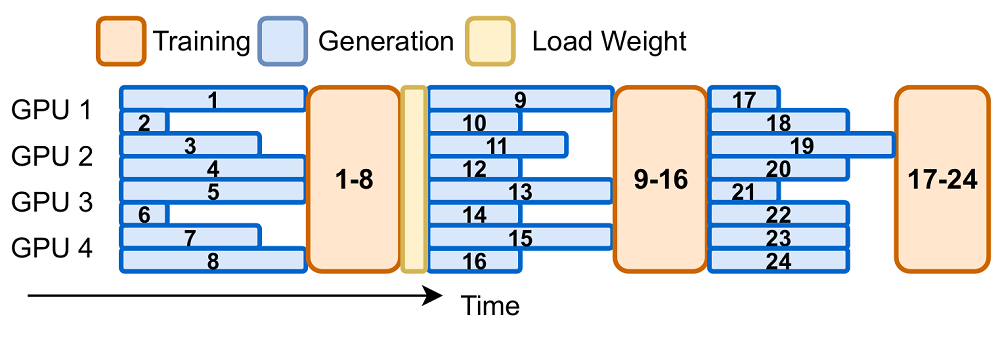
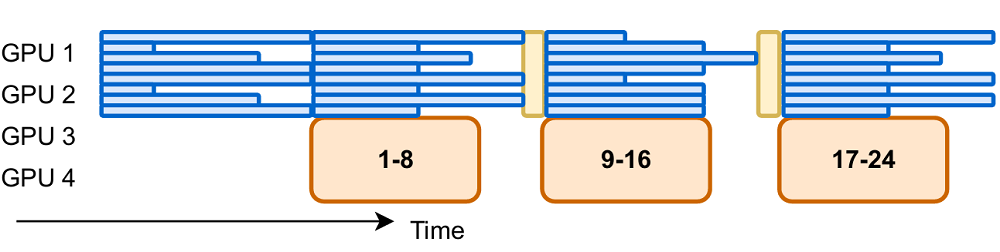
提升设备利用率
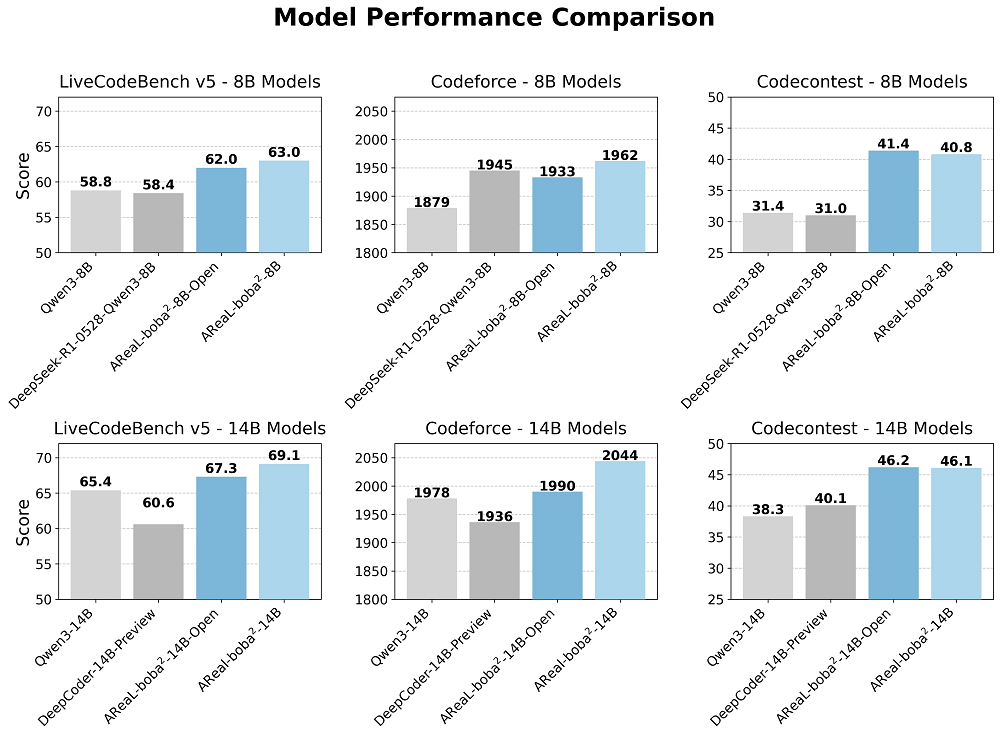
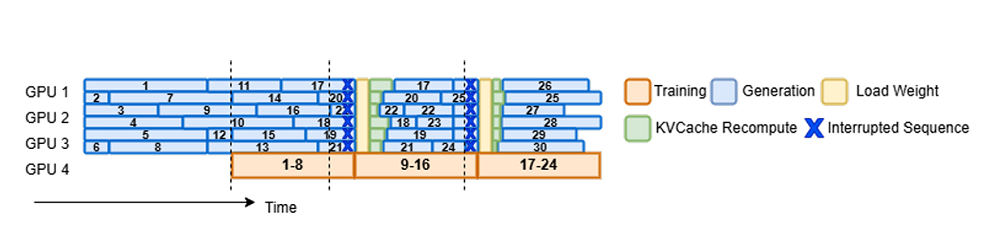
该强化学习系统中,若干GPU正专注于执行生成任务,以减少资源浪费。在训练环节,系统已配置128张显卡对1.5亿参数的模型进行训练。输出长度设定为32k,批处理大小为512乘以16。引入异步训练方法后,相较于同步方法,每个训练步骤的平均耗时降低了52%。
长文本生成优势
AReaL - boba²在处理长文本生成任务上展现出非凡的能力。该系统运用了异步与可中断的生成模式。这种设计使得生成过程所需时间得到有效掩盖。因此,整体工作效率得到了显著提升。在系统设计方面,其可中断的生成策略降低了训练过程中的等待时间,此外,动态微批次分配策略的应用,使得系统在各类规模模型中的处理能力提高了大约30%。
行业内外均高度关注,针对AReaL - boba²这一异步强化学习系统的未来发展,各界普遍表现出浓厚的兴趣,对其是否能够引领强化学习领域的新趋势充满疑问。我们衷心期望在评论区听到您的观点,同时,诚挚地邀请您对本文进行点赞及转发,以此表达您的支持。

 网站首页
网站首页 关于商会
关于商会 商会动态
商会动态 商会会员
商会会员 会员之家
会员之家 信息平台
信息平台 中小企业
中小企业 联系我们
联系我们