
人工智能领域内,多模态大型模型持续受到广泛关注,但其在特定场景和任务上的表现不尽如人意,这一状况已成为制约其发展的关键问题。近期,研究团队推出了一系列创新性策略,并取得了显著成效,为该领域注入了新的活力,同时也指明了未来发展的可能路径。
多模态现状
近期,在图像及视频等视觉语言处理领域,多模态大型模型取得了显著进展。然而,在特定场景的任务执行上,其性能提升仍有很大的提升空间,这已成为人工智能领域迫切需要解决的问题。这种现象可以比作长跑选手在不同路段可能展现出的竞技状态差异,目前,多模态大模型在全场景应用方面尚未完全展现出其理想的全能性能。
新架构的提出
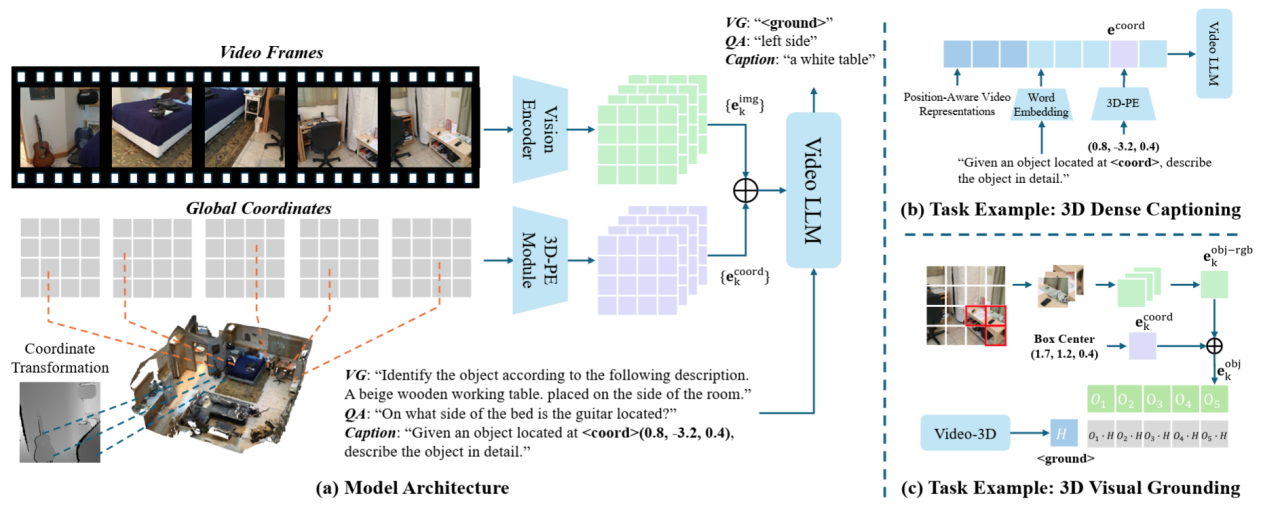
该团队研发了一套全面的多任务学习体系,这一体系能够对视觉定位、详尽描述以及问答等任务进行端到端的学习与训练。在3D数据处理效率上,该架构表现出色,为机器人、自动驾驶等领域的空间认知任务提供了新的研究途径。该模型的问世,宛如为该领域开启了一扇新的大门,赋予了其前所未有的能力。
实现跨帧理解
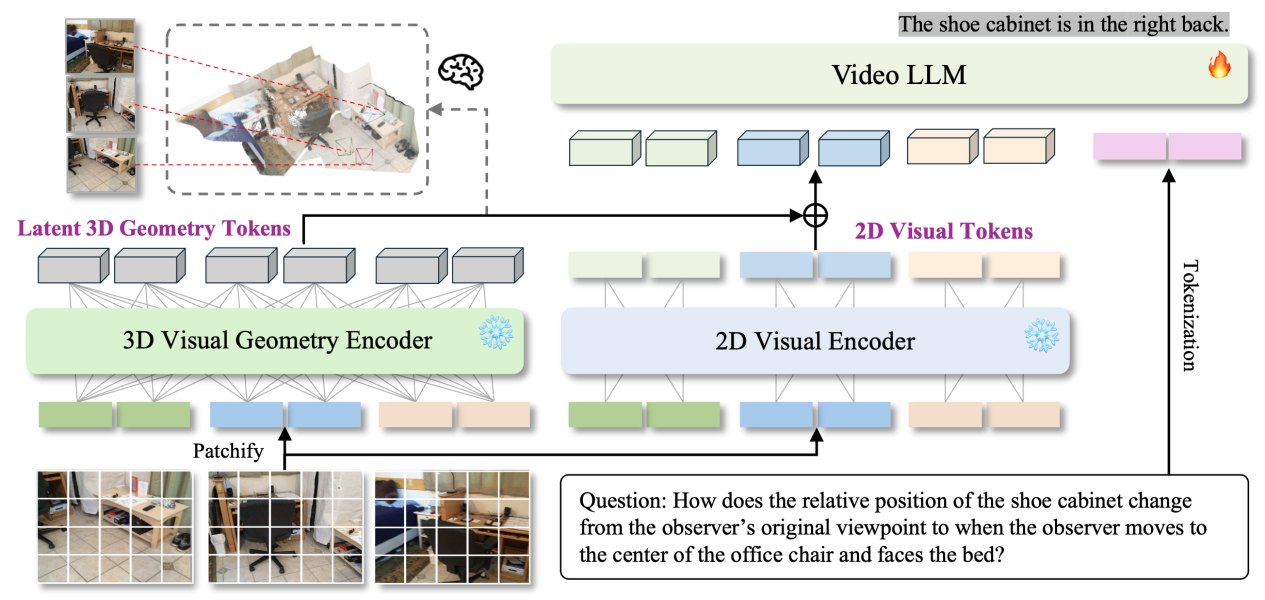
该技术已成功建立了坐标系的一致性模型,该模型以首帧坐标系统为基准。无需依赖相机参数,即可实现跨帧间的空间关系构建。同时,对跨帧空间的一致性进行了深入研究。它突破了传统方法对相机参数或三维输入数据的依赖,能够直接从视频输入中预测并执行三维空间的智能任务。在多个三维理解和空间推理任务中,该技术展现了其实用性和有效性。

模型实力展现

在3D视觉定位等关键任务的评估中,Video-3D Geometry LLM模型凭借其庞大的4B参数量,表现出卓越的执行效能。具体而言,在3D视觉定位领域,该模型能够将3D定位信息转换为视频中的时空坐标,无需依赖点云数据,即可直接预测出定向的3D边界框,并取得了出色的性能表现。在空间推理领域的权威基准测试VSI-Bench中,VG LLM的表现尤为出色,其平均得分显著领先。具体来看,该模型的成绩超越了Gemini 1.5 Pro和GPT-4o等多个备受瞩目的商业级大型模型。
评测难题待解
当前,人工智能在处理多模态大型视频内容方面存在局限。与此同时,传统的长视频标注工作成本高昂,操作流程复杂。学术界与工业界迫切需要一种既经济又高效的解决方案,以构建动态视频语言评测的标准。这一难题亟待解决,而创新性的方法亦需积极寻求。
新方法降成本
研究团队创新性地提出了一种视频语言表征技术,该技术基于视觉基础模型,有效地从视频中自动提取场景与对象信息。实验数据显示,该技术大幅降低了测试平台评测数据的准备工作量,成本降低幅度超过70%。而且,该方法还能以高效且经济的方式,从零开始搭建一个可扩展的视频语言评测标准。此外,本方法可借助凤凰卫视的视频资源,进而实现问答评测标准的动态构建。
各界人士纷纷进行推测,对于多模态大型模型在全场景中实现高效应用的时间节点,这一话题引起了广泛的讨论。在此,我们诚挚邀请各位在评论区发表您的看法。同时,敬请别忘了点赞并转发本篇文章。

 网站首页
网站首页 关于商会
关于商会 商会动态
商会动态 商会会员
商会会员 会员之家
会员之家 信息平台
信息平台 中小企业
中小企业 联系我们
联系我们